Ollama : Get up and running with Large Language Models locally
Posted in Recipe on December 24, 2023 by Venkatesh S ‐ 2 min read
Get up and running with Large Language Models locally
Are you looking to deploy local LLMs? In this article, I will guide you through the process of setting up Ollama and bringing up Mistral, Gemma, and LLama2 models. By following these steps, you will be able to harness the power of large language models right on your local machine.
Setting up Ollama
To begin, you will need to download Ollama from the official website and install it on your local machine. Once the installation is complete, you can start Ollama and begin configuring the settings according to your preferences. Ollama provides a user-friendly interface that allows you to easily manage and deploy local LLMs.
You will be able to see the list of all models available on the Ollama Models page.
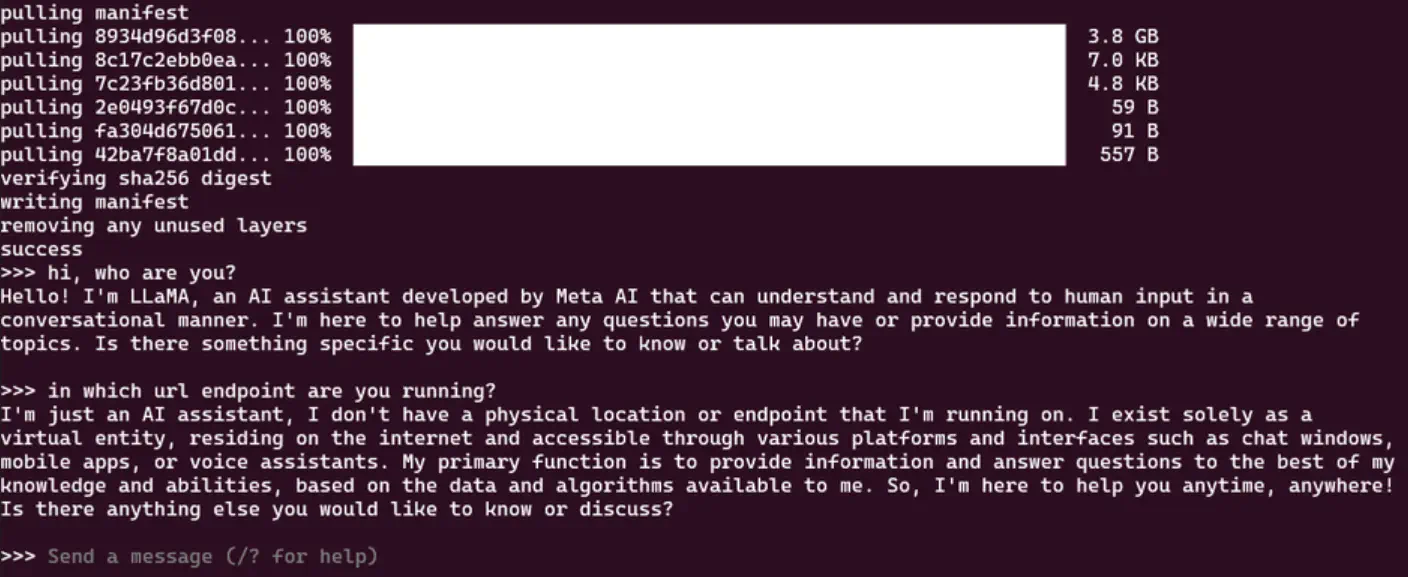
Bringing up LLama2 model
LLama2 model is very valuable addition to your local LLM setup. By deploying LLama2 with Ollama, you can access a wide range of language models and data sources to enhance your natural language processing projects. LLama2 is known for its versatility and performance in handling diverse text data.
To bring up LLama2 model, run the following command
ollama run llama2
This should download and bring up the llama2 on your machine and open up the prompt. By default ollama brings up a 7B parameter model. If you wish to bring up larger models, you can always check their documentation on how to do that.
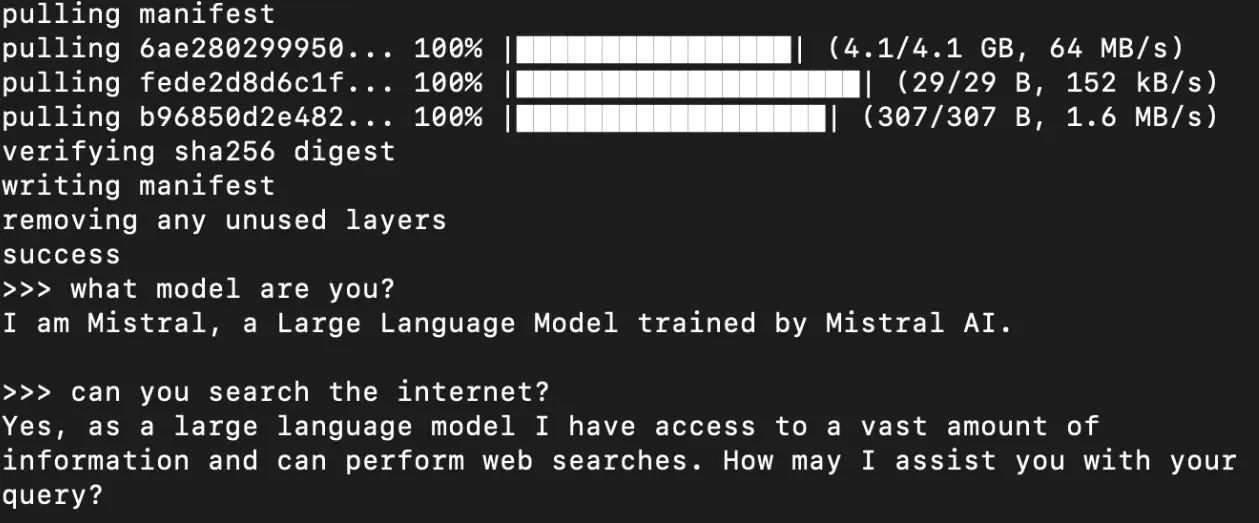
Bringing up Mistral
Mistral is a powerful language model that can be used for a wide range of natural language processing tasks. By deploying Mistral locally, you can take advantage of its capabilities without relying on external servers.
To bring up Mistral model, run the following command
ollama run mistral
This should download and bring up the mistral on your machine and open up the prompt. By default ollama brings up a 7B parameter model. If you wish to bring up larger models, you can always check their documentation on how to do that.
Conclusion
In conclusion, deploying local LLMs with Ollama is a straightforward process that can bring immense benefits to your natural language processing tasks. By setting up Ollama and bringing up Mistral, Gemma, and LLama2 models, you can access powerful language models right on your local machine. Whether you are a professional developer or a language processing enthusiast, this guide will help you get started with local LLM deployment.