Language Translation using M2M100 1.2B Model and Hugging Face Pipeline
Posted in Recipe on May 23, 2023 by Venkatesh S ‐ 2 min read
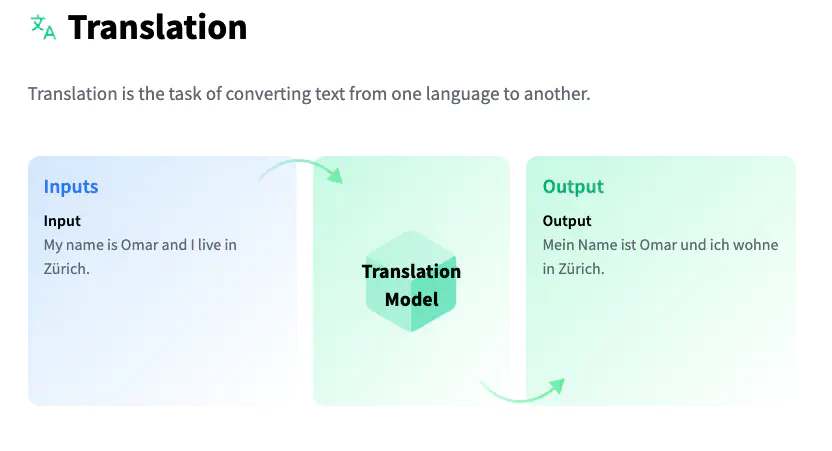
What is this post about?
There are many situations were we would need to do something related to machine learning. The typical approach anyone would follow in such scenarios is to go to an ML expert, discuss with him the use-case and then allow him to build a model, train it, test it and then use the model created to solve our business problem.
While may be a preferred approach, we can also consider the following options.
Look at some of the pre-trained models available to us and use them as per our requirement.
Look at some of the pre-trained models available, add our data on top of these models and use it as per our requirement
I have been fortunate to try these out and would like to discuss how easy it is to do it. The use-case we are discussing here is about translation from one language to another.
Using Pre-Trained Models
As of now if you check on hugging face models for translation, there are around 2117 models.
Today I would talk about using one of these models from Meta M2M100 1.2B that can be used for translating to and from more than 200 languages.
Translation Task
The notebook is available at the github url for reference.
Before we start the translation task, ensure that the following python libraries are installed.
# packages required for creating the pipeline and loading pre-trained models
pip install transformers datasets -q
# packages required for tokenization
pip install sentencepiece sacremoses -q
Import the required libraries
from transformers import pipeline, AutoTokenizer, AutoModelForSeq2SeqLM
import torch
The translation process using hugging face pipeline is a 4 step process.
- Set the device
device = torch.cuda.current_device() if torch.cuda.is_available() else -1
- Load the pre-trained model
model_name = 'facebook/m2m100_1.2B'
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
- Load the Tokenizer
# source language is hindi and target language is english
tokenizer = AutoTokenizer.from_pretrained(model_name, src_lang="hi", tgt_lang="en")
- Create a Hugging Face Pipeline
translator = pipeline('translation', model=model, tokenizer=tokenizer, src_lang="hi", tgt_lang="en",device=device)
- Translate the text
text = "यह वास्तव में आश्चर्यजनक है, क्योंकि यह महान अनुवाद करने में सक्षम है।"
target_seq = translator(text)
print(target_seq [0]['translation_text'])
You should see the output that is something like this “This is really amazing, because it is able to translate great.”
That is all, you can also expose this as an API service and create a great interface like google translate and use them in your projects.